在人工智能和自然语言处理领域,语音对话模型一直是研究的热点,也是非常重要的人机交互入口。目前所有的智能对话都需要基于知识语料库,或者LLM大模型加ASR,TTS等基础AI模型对语音语文字进行转化实现模拟人类的语音交互过程,这类方案有个最大的问题延迟非常大,非常影响人机对话体验。也是大多数人机对话产品使用率不高,用户不喜欢和机器对话的原因,而且对话内容不能识别到情感语调的区别。
先看网友发布实测视频,时长00:44
Moshi是由Kyutai Labs开发的一个开源语音对话模型,旨在提供高质量、自然的语音交互体验,可以略过 ASR,TTS 的过程让人类直接对话语音大模型,而且这个过程延迟降低到了不可思议的几百毫秒,我在实际体验的过程中最大的感受是,和面对面交流非常接近,有轻度情绪有情感表现,甚至在聆听的过程中可以快速打断人类的对话。
简单来说,Moshi就像一个聪明的助手,它能同时听到你说的话和自己要说的话,通过快速的音频处理和智能的语言理解,给出自然的回应。它的设计让人机对话变得更加顺畅和真实,仿佛你在和一个真正的朋友交流。
Moshi的源代码托管在GitHub上,可以在https://github.com/kyutai-labs/moshi 找到。
以下是试用地址:

Moshi的主要特点
1. 开源性:Moshi是完全开源的,这意味着研究人员和开发者可以自由地使用、修改和改进这个模型。
2. 高性能:Moshi采用了先进的深度学习技术,能够提供流畅、自然的语音对话体验,几乎感受不到延迟。
3. 可定制性:作为开源项目,Moshi允许用户根据特定需求进行定制和优化。
Moshi的技术原理
Moshi模型同时处理两个音频流:一个对应Moshi自身的语音,另一个对应用户的语音。在实际应用中,用户的音频流来自音频输入,而Moshi的音频流则由模型的输出采样生成。除了这两个音频流,Moshi还预测与自身语音相对应的文本标记,这被称为”内心独白”,大大提高了其生成质量。
1. 双向语音流:
Moshi同时处理两种声音:一种是用户说的话,另一种是机器生成的回应。想象一下你和朋友对话,你说一句话,朋友回应你,Moshi就是在模拟这种对话。
2. 音频处理:
Moshi使用一个叫做Mimi的音频编解码器。这个编解码器可以快速处理声音,几乎没有延迟(大约80毫秒)。这意味着你说话后,机器几乎立刻就能理解并回应你。
3. 内心独白:
在对话过程中,Moshi不仅仅是听用户说的话,它还会预测自己应该说什么。这种预测被称为“内心独白”,就像人类在思考下一句话时的内心活动一样。这使得机器的回应更加自然和流畅。
4. 使用转换器(Transformer):
Moshi使用了一种叫做“转换器”的技术来理解和生成语言。转换器可以帮助模型理解上下文和时间关系,确保机器的回应是合适的。例如,如果你问“今天天气怎么样?”,机器会理解你在询问天气,而不是其他话题。
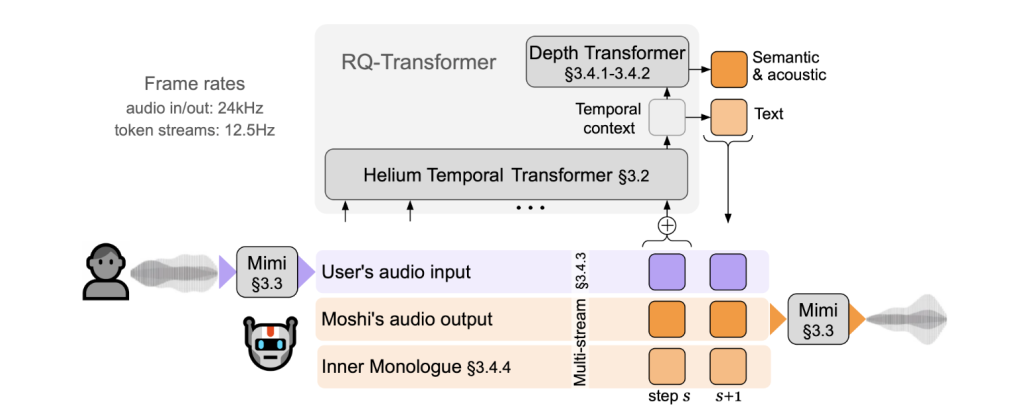
Moshi使用两个转换器(Transformer)来处理信息:
1. 一个小型的深度转换器,用于模拟给定时间步长的编码本间依赖关系。
2. 一个大型的、拥有70亿参数的时间转换器,用于模拟时间依赖关系。
理论上,Moshi可以实现160毫秒的延迟(Mimi的80毫秒帧大小加上80毫秒的声学延迟)。在实际应用中,使用L4 GPU可以将整体延迟降低到200毫秒左右。
Moshi的核心是Mimi音频编解码器。它在之前的神经音频编解码器(如SoundStream和EnCodec)基础上进行了改进:
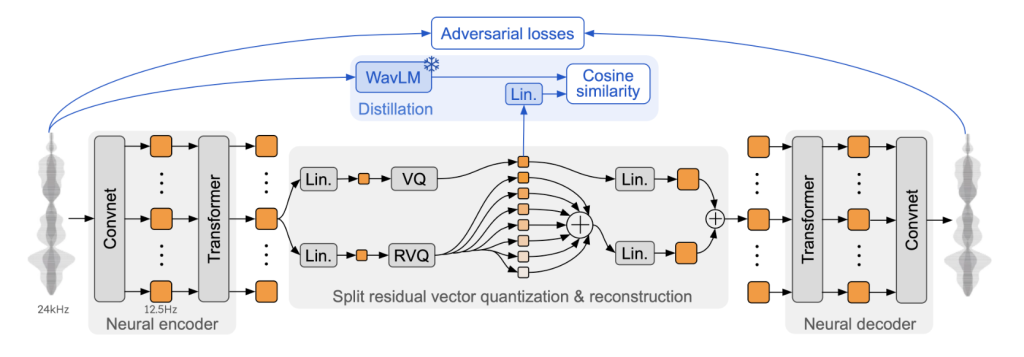
在编码器和解码器中都添加了Transformer。
调整了步幅以匹配12.5 Hz的整体帧率。
使用蒸馏损失,使第一个编码本标记与来自WavLM的自监督表示相匹配。
仅使用对抗性训练损失和特征匹配,显著提高了主观质量。
Moshi的应用前景
Moshi语音对话模型的出现标志着语音交互技术的一个重要进步。它通过低延迟的实时交互、双向语音流处理、内心独白机制等创新,提升了人机对话的自然性和智能性。随着技术的不断发展,Moshi有望在未来的智能设备和应用中发挥更大的作用,推动人机交互的变革。Moshi的出现为实时语音对话系统带来了新的可能性。可以预测到可能在以下领域产生重大影响:
1. 智能助手:提供更自然、响应更快的语音交互体验。
2. 客户服务:实现更高效、更人性化的自动语音客服系统。
3. 语音翻译:支持近乎实时的多语言口译。
4. 教育:开发更智能的语音交互学习系统。
5. 无障碍技术:为听障人士提供更好的语音转文本服务。