常规的知识库检索通常使用的是关键字与词条匹配,随着AGI的爆发,越来越多的知识库检索开始使用向量检索技术,特别是在RAG领域,增强型的生成式问答检索正在大面积应用和推广。
那向量检索和普通检索在特性上的区别很好理解:
普通检索:
优化于查找精确的关键字或短语匹配,主要依赖于关键字匹配来提供搜索结果,适用于简单查询和确切匹配的场景,无法处理语义关系和复杂数据类型。
优点:灵活性高,查询逻辑透明易懂,可维护性强,存储查询成本低。
缺点:关键字匹配,无法理解语义,查询质量提升困难。
向量检索:
利用数学向量表示数据,计算数据点之间的相似性或距离,能够处理语义关系,上下文和数据的丰富语义信息,适用于处理图像、音频、视频等多种数据类型,提供更准确和相关的搜索结果,不仅仅依赖于关键字匹配。
优点:语义理解能力强,向量检索基于文档的向量表示,对多义词和同义词的处理更为准确。
缺点:数据存储,计算成本较高,不同类型数据的查询算法不同,查询算法需要不断优化。
从上面对比分析来看,传统检索方法更适合准确匹配的场景,向量检索适合复杂语义匹配检索需求,可以理解更复杂的语义关系,提供更为准确和全面的检索结果。特别是在一些知识问答场景,如人工客服,知识库检索等方面,一个问题有很多种描述方法,所以在通过向量查询的方式中,根据相似度计算后会最大可能得检索到所有相关的答案,然后按照最佳匹配的权重返回最理想的结果,如大模型中的RAG应用。
除了刚才提到的基于知识库的问题系统用到了向量检索,向量检索的应用场景非常多,比如:
- 推荐系统:广告推荐、猜你喜欢等;
- 图片识别:以图搜图,通过图片检索图片。具体应用如:车辆检索和商品图片检索等;
- 自然语言处理:基于语义的文本检索和推荐,通过文本检索近似文本;
- 声纹匹配,音频检索; 文件去重:通过文件指纹去除重复文件;
- 新药搜索;
然而针对不同数据类型和匹配逻辑,不同的检索数据和检索场景应用的检索算法也不一样,以下是几种基础的检索算法和应用场景简单介绍:
局部敏感哈希(LSH)
LSH(Locality Sensitive Hashing),中文叫做“局部敏感哈希”,它是一种针对海量高维数据的快速最近邻查找算法。我们经常会遇到的一个问题就是面临着海量的高维数据,查找最近邻。如果使用线性查找,那么对于低维数据效率尚可,而对于高维数据,就显得非常耗时了。为了解决这样的问题,人们设计了一种特殊的 hash 函数,使得 2 个相似度很高的数据以较高的概率映射成同一个 hash 值,而令 2 个相似度很低的数据以极低的概率映射成同一个 hash 值。我们把这样的函数,叫做 LSH(局部敏感哈希)。LSH 最根本的作用,就是能高效处理海量高维数据的最近邻问题。
应用场景: 海量高维向量数据的近似最近邻搜索,如大规模文本语义检索、个性化推荐等。 算法逻辑: 构建多个哈希函数族,每个函数将向量映射到一个哈希值。 对每个向量计算多个哈希值,作为该向量的签名。 将具有相同签名的向量存储在同一个桶中。 查询时,计算查询向量的签名,检索对应桶中的向量作为候选集。 在候选集中进行精确的相似度计算,返回最相似的K个向量。
示例: 在一个包含数百万条新闻文本的语义检索系统中,可以使用LSH将新闻文本映射为向量并构建索引。查询时将用户查询语句也映射为向量,通过LSH快速检索出与之最相似的新闻文本。
分层可导航小世界(HNSW)
HNSW(Hierarchical Navigable Small Word)其目的就是在极大量的候选集当中如何快速地找到一个query最近邻的k个元素。HNSW算法就是目前比较常用的一种搜索算法,它算是其前作NSW算法的一个升级版本,通过图连接的方式给所有的N个候选元素事先地定义好一个图连接关系,从而可以将前述的算法复杂度当中的N 的部分给减小掉,从而优化整体的检索效率。
应用场景: 亿级规模向量数据的近似最近邻搜索,如大规模图像检索、视频检索等。 算法逻辑: 将向量按插入顺序构建成多层次图结构,每层是上一层的导航对象。 新插入的向量与当前层的部分向量计算距离,选择最近的作为入口点。 从入口点出发,贪婪搜索最近邻,构建新向量的连接边。 查询时,从最顶层开始贪婪搜索,逐层找到最近邻向量。
示例: 在一个包含数十亿张图像的图像检索系统中,可以使用HNSW将图像特征向量构建索引。查询时将上传的图像特征向量输入,通过HNSW高效地检索出最相似的图像。
向量乘积量化(IVFPQ)
IVFPQ(Inverted File Product Quantization)是一种用于高效近似最近邻搜索的索引方法,结合了倒排文件索引(IVF)和产品量化(PQ)两种技术。IVFPQ通过将高维向量分解为较小的子空间,并对每个子空间进行独立的量化,从而实现了紧凑的表示和快速的相似性搜索。这种方法在处理大规模数据集时表现出色,既能够降低存储需求,又能加速查询处理。
应用场景: 海量高维向量数据的近似最近邻搜索,如大规模多媒体检索、电商商品检索等。 算法逻辑: 构建包含大量质心的预先计算的聚类簇,称为列表。 将向量分解为多个低维子向量,对每个子向量进行量化编码。 查询时,先找到与查询向量最近的列表,再对该列表中的向量进行距离计算。
示例: 在一个包含数亿件商品的电商平台中,可以使用IVFPQ将商品图像、文本等特征向量构建索引。查询时输入用户查询,通过IVFPQ快速检索出最相似的商品。
到此我们对向量检索技术有了一些大概的了解,对于图片媒体基于向量的查询可以很好的理解,但是对于文本相似度与语义理解上改如何使用向量进行表达?文本相似度表达语义,在这里要引入一个NLP–文本向量化,即向量语义(vector semantics)模型,目前常见的向量语义模型会根据不同的领域有不同领域的向量语义模型,如我们可以在modelscope上找到很多领域的文本向量模型,这些文本向量模型也是根据当前领域中的语料数据进行针对性的训练生成。
如:
通用中文文本向量
text2vec-large-chinese
https://modelscope.cn/models/thomas/text2vec-large-chinese/summary
电商领域文本向量
nlp_corom_sentence-embedding_chinese-base-ecom
https://modelscope.cn/models/iic/nlp_corom_sentence-embedding_chinese-base-ecom/summary
医疗领域文本向量模型
nlp_corom_sentence-embedding_chinese-base-medical
https://modelscope.cn/models/iic/nlp_corom_sentence-embedding_chinese-base-medical/summary
这些向量模型都会根据用户输入原始信息转换为对应模型的向量数据.
例如在医疗向量模型中输入一个句子, 会输出一个固定维度的连续向量:
- 输入: 上消化道出血手术大约多少时间
- 输出: 0.16549307, -0.1374592 , -0.0132587 , …, 0.5855098 , -0.340697 , 0.08829002]
然后我们就可以根据输出的向量进行文本聚类、文本相似度计算匹配与检索。
那到这里又会出现一个疑问,文本的向量数据是如何计算出来的?那就要了解一下词的相似度计算方法,即向量空间模型建模。
向量空间模型是一种词义的表示方式。其基本出发点是将词嵌入到一个向量空间中,正因此,我们把一个词的向量表示称为一个词嵌入(embedding),一个单词由单词在词汇表中的索引来表示,或者用字母组成的字符串来表示。向量模型的一大优势在于,他可以更加细粒度的表示一个词的语义,而非像一个索引,一个字符串那样把单词看作一个原子。
词向量一般使用上下文词来刻画词,这样可以更加细粒度的刻画一个词。因此,我们的矩阵将是一个|V|*|V|维的矩阵。行和列都是语料集中的词汇,矩阵元素表示两个词汇出现在同一个上下文中的次数,那么矩阵元素值就是两个单词出现在同一个文档中的次数。
比我我们有一段话中高频出现的词分布到矩阵中:
| – | aardvark | computer | data | pinch | result | sugar |
|---|---|---|---|---|---|---|
| apricot | 0 | 0 | 0 | 1 | 0 | 1 |
| pineapple | 0 | 0 | 0 | 1 | 0 | 1 |
| digital | 0 | 2 | 1 | 0 | 1 | 0 |
| information | 0 | 1 | 6 | 0 | 4 | 0 |
从上面表中可以看出,apricot 和 pineapple 是相似的,因为它们的上下文中都出现了 pinch 和 sugar,但是 digital 的上下文就没有这些词。因此可以发现,词的关系似乎潜藏在这个矩阵之中。
也可以简单的理解为:
apricot的向量值为[0,0,0,1,0,1]
pineapple的向量值为[0,0,0,1,0,1]
两个单词有相同的向量,则两个单词的语义相同或者接近。
实际在模型训练与优化中,词汇量会更大,进行优化的算法也会更复杂。
如上文提到的word2vec不是一个单一的算法,而是一系列模型架构和优化。
常用的算法模型有
- CBoW连续词袋模型
根据周围的上下文词预测中间词。上下文由当前(中间)单词之前和之后的几个单词组成。这种架构称为词袋模型,因为上下文中的单词顺序并不重要。
- Continuous Skip-Gram模型
预测同一句话中当前单词前后一定范围内的单词。下面给出了一个可行的例子。
完整的向量模型计算过程是一个神经网络训练的过程,可表示如下:
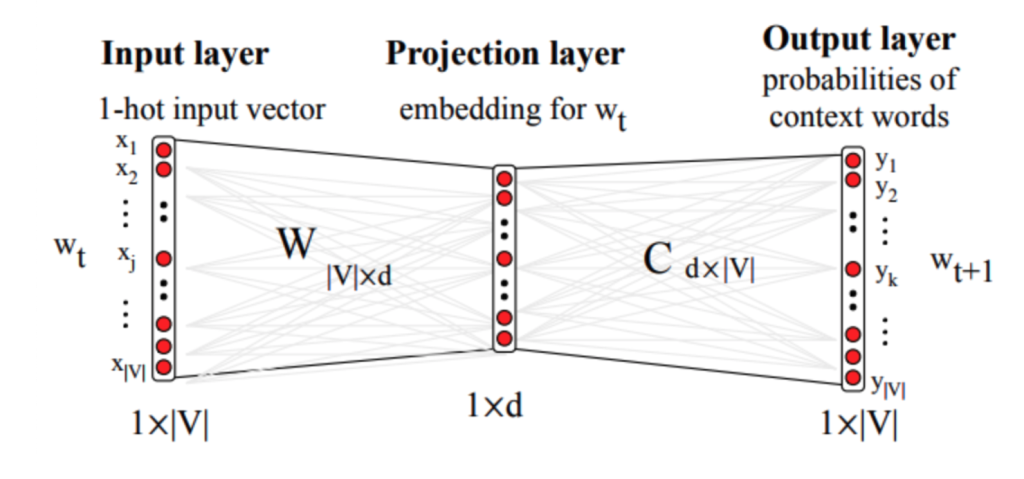
其中输入是单词的 1-hot 编码(只有一个维度为 1 的向量,向量维度总数等于词汇表大小),用于从词向量 W 中取出当前词对应的向量,其中 C 是上下文词向量。W 和 C 都是随机初始化的,通过训练过程不断调整。最终我们希望获得的产物就是 词向量矩阵 W。共 |V| 行,每一行对应词汇表中的一个词的词向量。
最后到输出层,输出层,需要进行优化有压缩,方便向量存储与检索,这个又会涉及到向量模型优化的一些知识点,这个可以有兴趣可以参考word2vec完成算法模型进行研究: